

发布时间: 2023-04-06 17:48:36 发布者:togogo |
Hadoop是为处理大型文件所设计的,在小文件的处理上效率较低,然而在实际生产环境中,需要Hadoop处理的数据往往存放在海量小文件中。因此,高效处理小文件对于提高Hadoop的性能至关重要。这里的小文件是指小于 HDFS中一个块(Block)大小的文件。
Hadoop处理小文件有两种方法:压缩小文件和创建序列化文件。
Hadoop在存储海量小文件时,需要频繁访问各节点,非常耗费资源。如果某个节点上存放1000万个600Byte大小的文件,那么该节点上至少需要提供4 GB的内存。为了节省资源,海量小文件在存储到HDFS之前,需要进行压缩。
1.Hadoop压缩格式
Hadoop进行文件压缩的作用:减少存储空间占用,降低网络负载。这两点对于Hadoop存储和传输海量数据非常重要。Hadoop常用的压缩格式,如表所示。
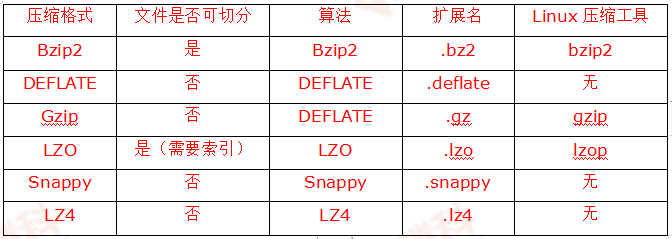
2.编解码器
编解码器(Codec)是指用于压缩和解压缩的设备或计算机程序。Hadoop中的编压缩解码器主要是通过Hadoop的一些类来实现的, 如表所示。

对于LZO压缩格式,Hadoop实现压缩编解码器的类不在org.apache.hadoop.io.compress包中,可前往GitHub官方网站下载。
3.压缩格式的效率
对上述6种压缩格式的压缩效率、解压效率、压缩占比进行测试,测试结果如下。
压缩效率 (由高到低): Snappy > LZ4 > LZO > Gzip > DEELATE > Bzip2
解压效率 (由高到低): Snappy > LZ4 > LZO > Gzip > DEELATE > Bzip2
压缩占比 (由小到大): Bzip2 < DEELATE < Gzip < LZ4 < LZO < Snappy
在实际生产环境中,可以参考以上的测试结果,根据业务需要做出恰当的选择。
创建序列文件主要是指创建SequenceFile(顺序文件)和MapFile(映射文件)。
1.SequenceFile
(1)SequenceFile简介。
SequenceFile是存储二进制键值(Key-Value)对的持久数据结构。通过SequenceFile可以将若干小文件合并成一个大的文件进行序列化操作,实现文件的高效存储和处理。
(2)SequenceFile的内部结构
SequenceFile由一个文件头(Header)和随后的一条或多条记录(Record)组成(如图所示)。Header的前三个字节SEQ(顺序文件代码),随后的一个字节是SequenceFile的版本号。Header还包括Key类的名称、Value类的名称、压缩细节、Metadata(元数据)、Sync Marker(同步标识)等。Sync Marker的作用在于可以读取SequenceFile任意位置的数据。
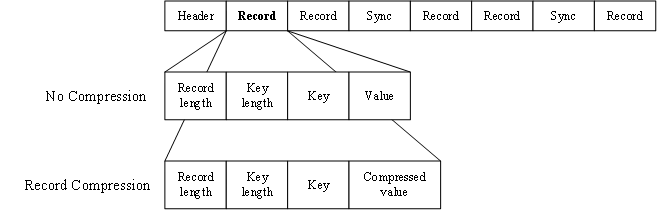
记录有无压缩、记录压缩、块压缩三种压缩形式,默认为无压缩。
① 当采用无压缩(No Compress)时,每条记录由记录长度、键长度、键、值组成,将键与值序列化写入SequenceFile。
② 当采用记录压缩(Record Compress)时,只压缩值,不压缩键,其他方面与无压缩类似。
③ 块压缩(Block Compress)利用记录间的相似性进行压缩,一次性压缩多条记录,比单条记录的压缩方法压缩效率更高。
当采用块压缩时,多条记录被压缩成默认1MB的数据块,每个数据块之前插入同步标识。数据块由表示数据块字节数的字段和压缩字段组成,其中,压缩字段包括键长度、键、值长度、值。
下一篇: 软考是什么?应该怎么选择方向?

微信

公众号










