

发布时间: 2023-02-13 11:33:16 发布者:togogo |
| count | 非 NA 值的数量 |
| describe | 针对 Series 或 DF 的列计算汇总统计 |
| min , max | 最小值和最大值 |
| argmin , argmax | 最小值和最大值的索引位置(整数) |
| idxmin , idxmax | 最小值和最大值的索引值 |
| quantile | 样本分位数(0 到 1) |
| sum | 求和 |
| mean | 均值 |
| median | 中位数 |
| mad | 根据均值计算平均绝对离差 |
| var | 方差 |
| std | 标准差 |
| skew | 样本值的偏度(三阶矩) |
| kurt | 样本值的峰度(四阶矩) |
| cumsum | 样本值的累计和 |
| cummin , cummax | 样本值的累计最大值和累计最小值 |
| cumprod | 样本值的累计积 |
| diff | 计算一阶差分(对时间序列很有用) |
| pct_change | 计算百分数变化 |
(1).fillna()会填充nan数据,返回填充后的结果
(2)pddata["a"].unique() 特征a的值出现的set——唯一值
(3).loc[]选取指定列进行操作——df.loc[行标签,列标签]
(4).iloc[]函数——只能通过行号索引:df.iloc[0:4]它是基于索引位来选取数据集,0:4就是选取 0,1,2,3这四行
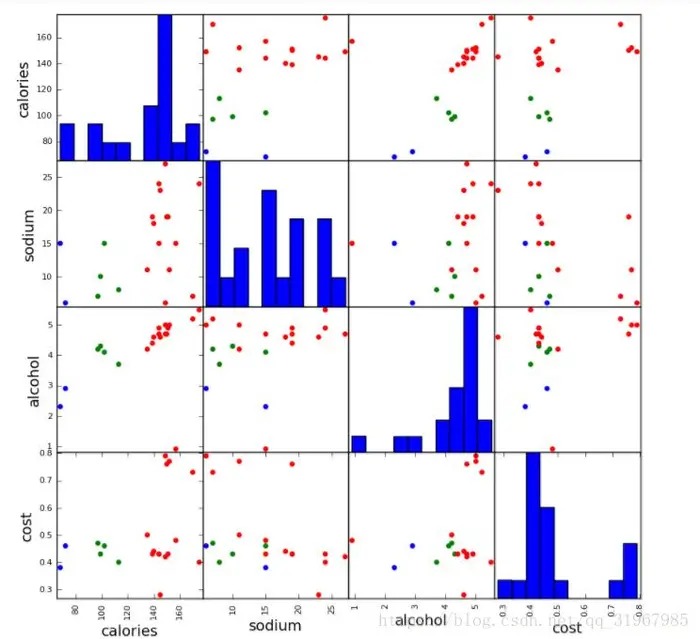
(5)作图
from pandas.tools.plotting import scatter_matrix(混淆散点图)
scatter_matrix(含有n个特征的数据X,s=100, alpha=1, c=colors[index], figsize=(10,10))
例如:scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=100, alpha=1, c=colors[beer["cluster"]], figsize=(16,16))
上一篇: 微服务架构的优势有哪些
下一篇: 软考备考需要多长时间完成

微信

公众号










