

发布时间: 2023-02-02 11:26:39 发布者:togogo |
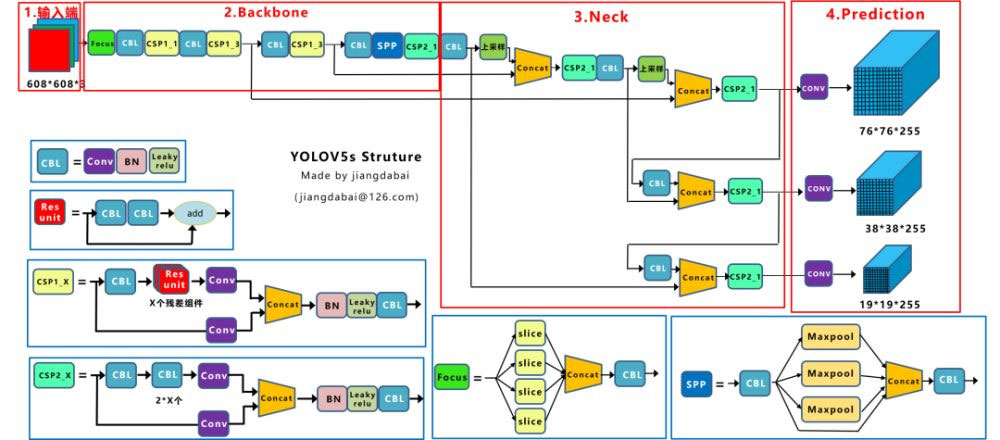
由上图可知,YOLO v5主要由输入端、Backone、Neck以及Prediction四部分组成。其中:
(1) **Backbone:**在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
(2) **Neck:**一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
(3) Head: 对图像特征进行预测,生成边界框和并预测类别。
下面介绍YOLO v5各部分网络包括的基础组件:
**CBL:**由Conv+BN+Leaky_relu激活函数组成
**Res unit:**借鉴ResNet网络中的残差结构,用来构建深层网络
**CSP1_X:**借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成
**CSP2_X:**借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成
**Focus:**首先将多个slice结果Concat起来,然后将其送入CBL模块中
**SPP:**采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合
YOLO v5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法
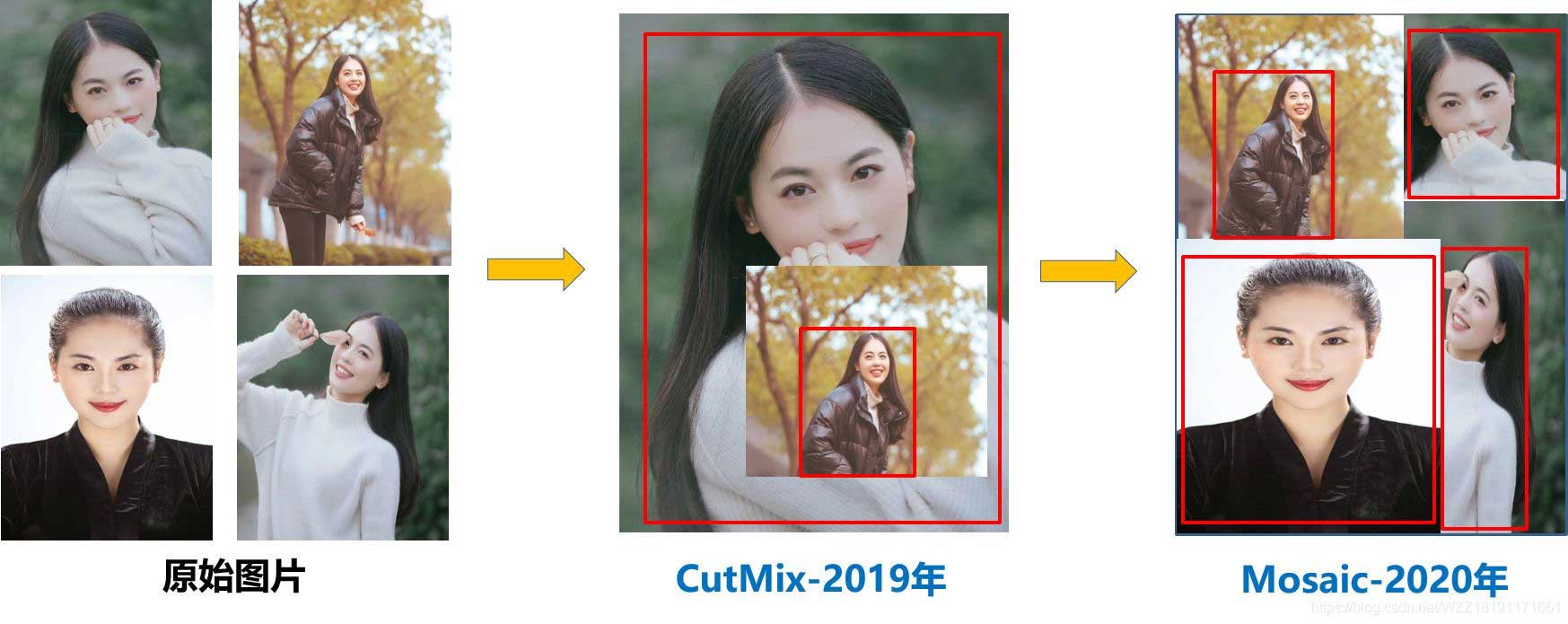
2.1Mosaic数据增强
Mosaic数据增强利用四张图片,并且按照随机缩放、随机裁剪和随机排布的方式对四张图片进行拼接,每一张图片都有其对应的框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。该方法极大地丰富了检测物体的背景,且在标准化BN计算的时候一下子计算四张图片的数据,所以本身对batch size不是很依赖
2.2 自适应锚框计算
在yolo系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框是比较关键的一环。
在yolo V3和yolo V4中,训练不同的数据集,都是通过单独的程序运行来获得初始锚点框。
而在yoloV5中将此功能嵌入到代码中,每次训练,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,指令为:

2.3 自适应图片缩放
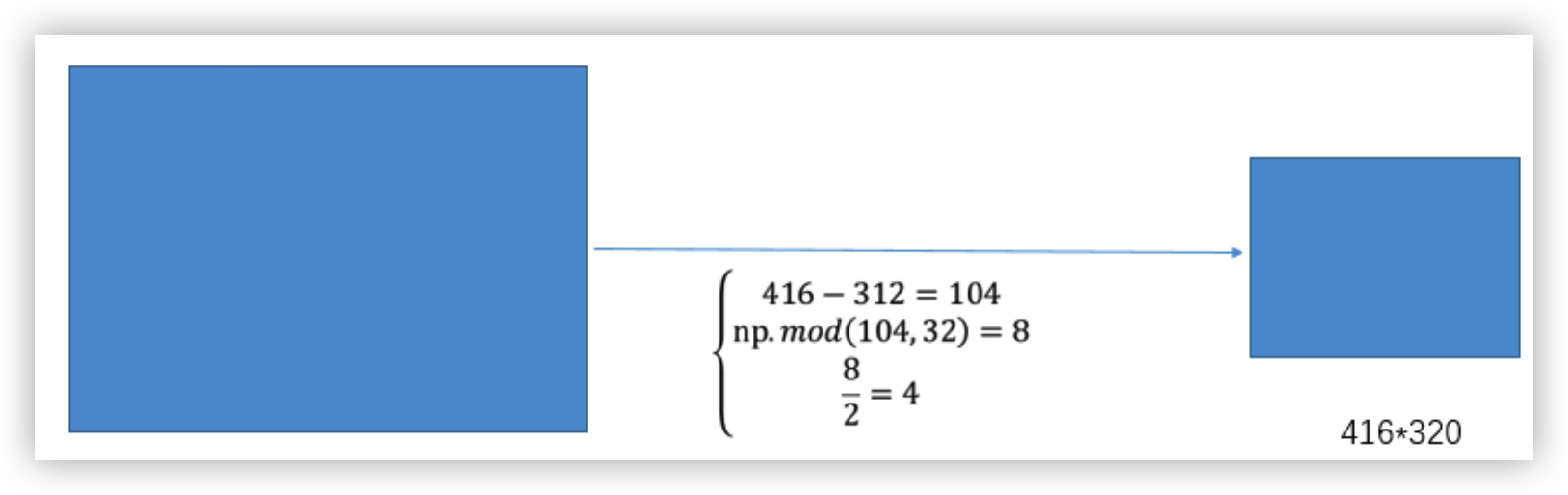
在目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。而原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLO v5的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。具体的实现步骤如下所述:
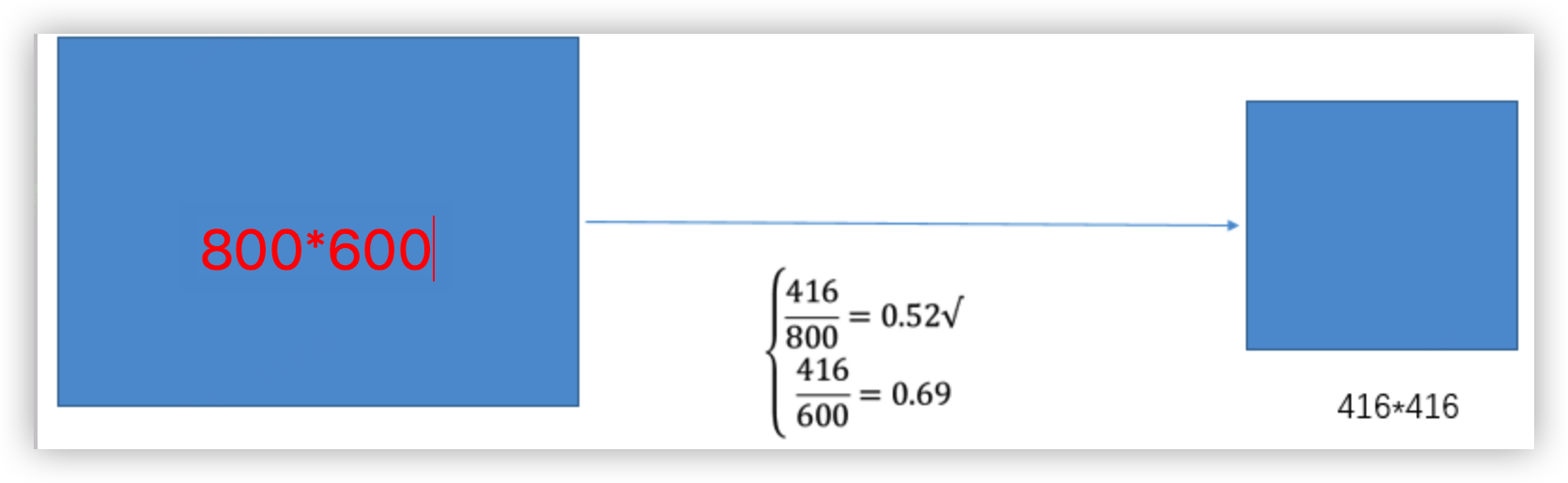
(1) 根据原始图片大小以及输入到网络的图片大小计算缩放比例
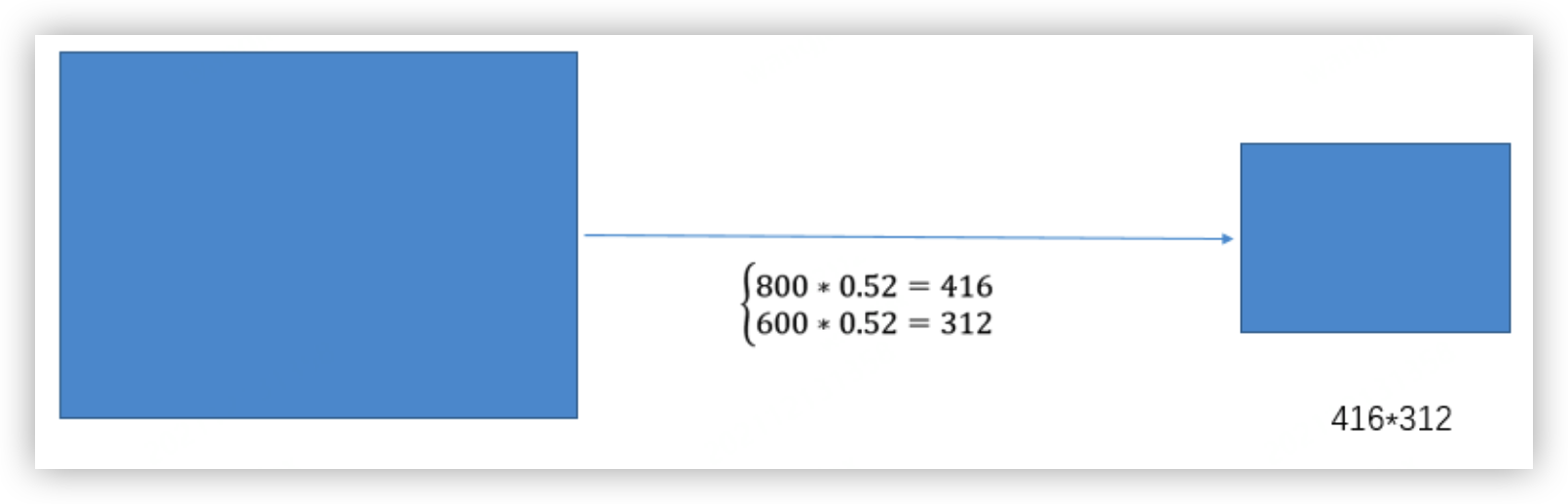
(2) 根据原始图片大小与缩放比例计算缩放后的图片大小
(3) 计算黑边填充数值
上一篇: Numpy数值计算基础
下一篇: cisp证书考试结果查询

微信

公众号










