

发布时间: 2022-05-19 10:28:28 发布者:togogo |


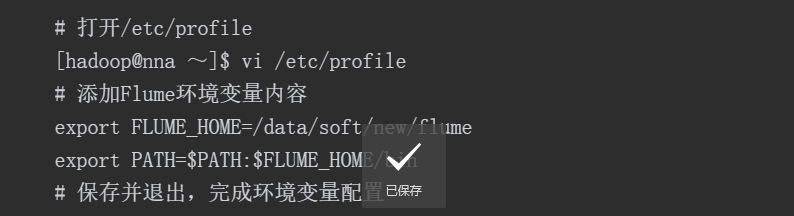
完成环境变量配置后,使用source命令使配置的环境变量立即生效。操作命令如下:




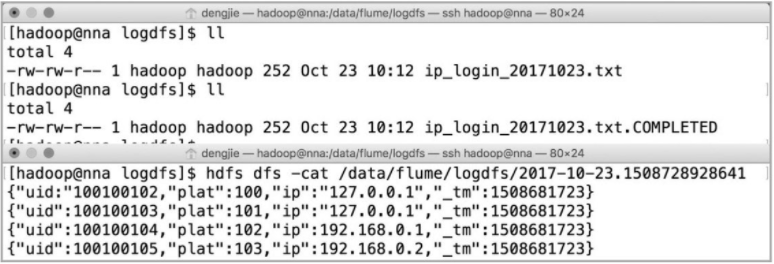
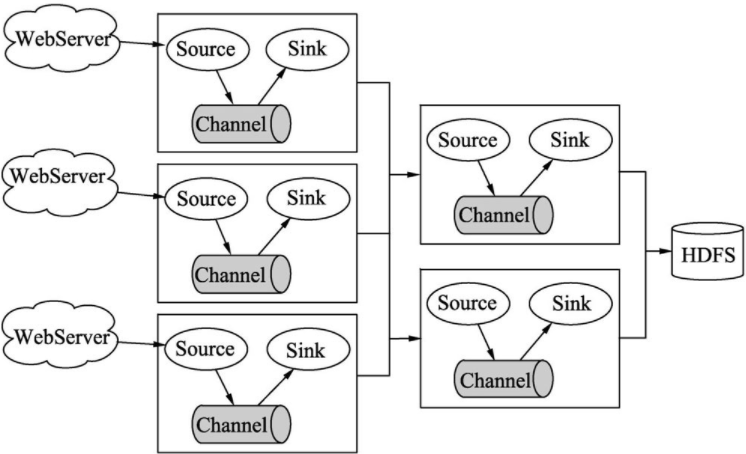
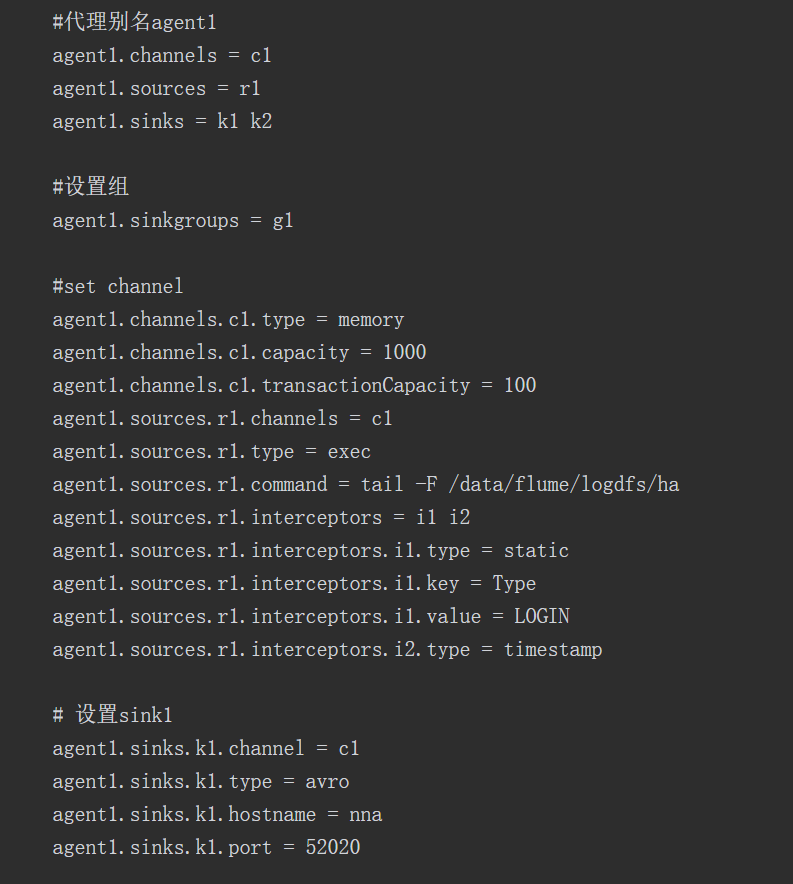
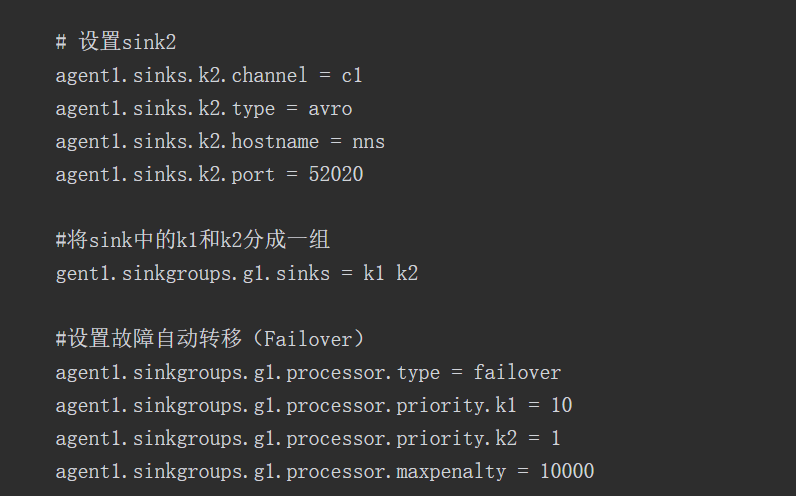
代码3 flume-server.properties文件

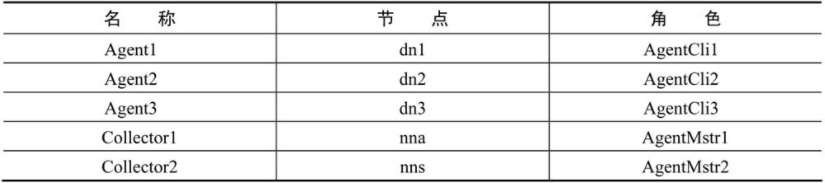
然后再使用scp同步命令,将nna节点上配置好的flume同步到nns节点作为Collector2(上传传备份服务),同时也同步到dn1、dn2、dn3上分别作为3个Agent(代理)客户端。操作命令如下:

上一篇: 网络安全问题产生的原因
下一篇: Sqoop安装步骤

微信

公众号










