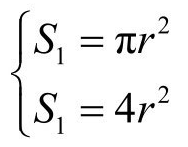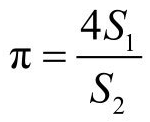什么是分布式计算?简单地说,分布式计算就是研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。
为了形象起见,这里举一个采用蒙特卡罗算法计算圆周率π的例子来具体说明什么是分布式计算。如图1所示,假设有一个内嵌圆形的正方形,圆的半径为r,面积为S1,正方形的边长为2r,面积为S2。
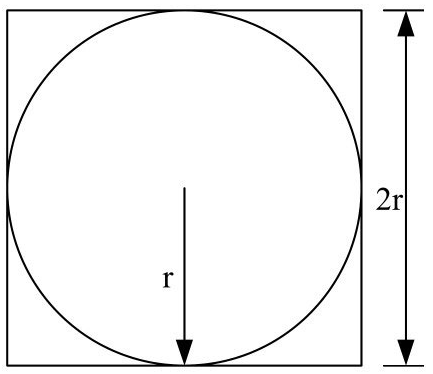
图1 π的计算方法
分别计算圆形和正方形面积,则得到如下公式。
计算推导可得如下公式。
接下来,根据上述推导结果我们可将圆周率的计算转换为以下计算任务。
(1)在正方形内随机生成一些点,假设其个数为x;
(2)计算这些点落在圆形内的个数,假设计算结果为y;
(3)则圆周率π=4y/x。
显然,x取值越大,圆周率的计算结果就越精确,但同时对计算资源的消耗也就越大。当x大到一定程度时,单个计算机已经无法在短时间内完成任务了。为此,我们需要对其进行拆分,得到以下分布式算法。
(1)在正方形内随机生成一些点,假设其个数为x;
(2)假设目前有m个计算机可用,则每个计算机分配的计算任务为x/m个点的随机统计;
(3)每个计算机分别计算这些点落在圆形内的个数,并各自得到计算结果为y1、y2、y3…
(4)假设这m台计算机中1台为主计算机,主机算机汇总各计算机的计算结果,得到y=y1+y2+y3+…;
(5)圆周率π=4y/x。
这个例子很简单,不过我想对于一个复杂的分布式计算任务来说,如何分配计算任务、计算过程中各计算节点间如何相互配合等问题可能还是挺难解决的。
的确如此,近来随着Google公司提出采用MapReduce计算模型并取得不错的应用效果以来,针对MapReduce技术的研究和探讨就变得越来越热门,它也称得上是云计算的标志性技术之一了。
什么是MapReduce呢?
我们还是用一个具体的例子来说明什么是MapReduce吧,假设要对三个句子中每个英文单词出现的次数进行统计,图2给出了采用MapReduce模型解决该问题的过程。
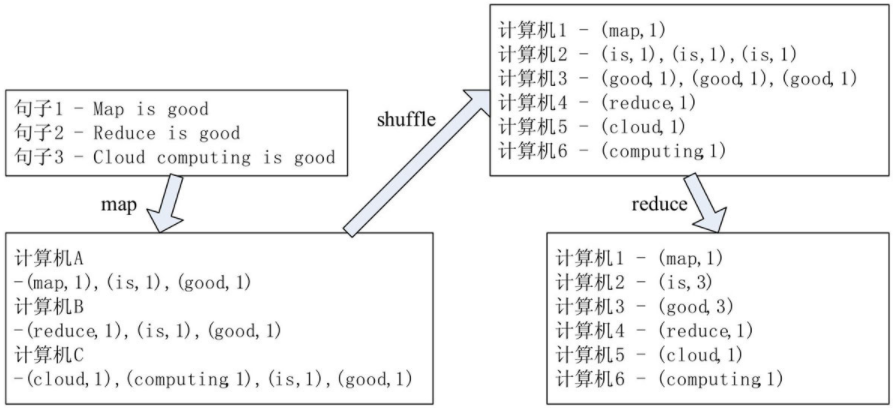
图2 MapReduce的基本原理具体来说,处理过程如下。
(1)分配计算任务,计算机A、B、C得到句子1、2、3的map任务;
(2)各计算机各自进行map处理,例如计算机A对句子1进行map处理后得到中间结果(map,1)、(is,1)、(good,1),,这里将map、is和good称为关键字,将关键字出现的次数(这里均为1)称为中间值;
(3)以中间结果里面的关键字对中间结果进行混排聚合处理(shuffle),并分配reduce计算任务,例如计算机2得到对三个(is,1)进行reduce处理的任务;
(4)各计算机各自进行reduce处理,得到统计结果,例如计算机2的reduce结果为(is,3),即表示单词is在三个句子中一共出现了三次。(5)汇总各计算机的结果即得到最终结果。
Google公司的MapReduce是怎么实现的?
如图3所示,Google公司在其MapReduce工作模型中定义了用户程序(User Program)、主服务器(Master)和工作服务器(worker)三种角色。
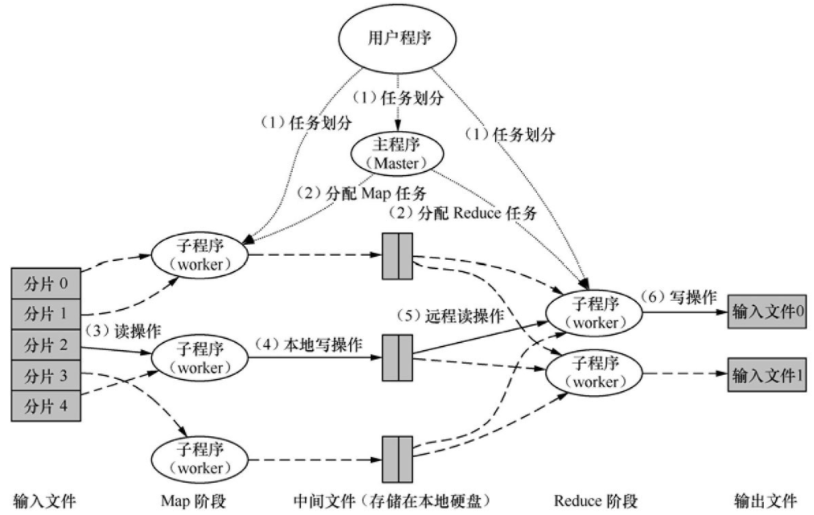
图3 Google的MapReduce
当用户程序需要发起一次MapReduce计算任务时,整个处理流程如下。
(1)用户程序调用MapReduce库将输入文件划分为多个块,每个块的大小一般为16~64MB(可以定制),然后启动主服务器和相关工作服务器;
(2)主服务器将map和reduce任务分配给空闲的工作服务器,并把划分好的输入数据块分配给各map任务;
(3)map任务对输入数据块进行处理,得到输入对,然后将这些对传递给用户编写的map函数,经处理后产生中间结果对;
(4)这些缓存在内存中的中间结果对被周期性地写入本地硬盘,同时map任务将存储位置上报给主服务器,再由主服务器告知reduce任务;
(5)当reduce任务接收到主服务器关于中间结果的位置通知后,它就从指定位置读取中间结果并同时以key为索引进行排序和聚合处理;
(6)reduce任务对聚合后的中间结果调用用户编写的reduce函数进行处理,处理结果被保存到输出文件中,如果一个reduce任务中出现多个key索引时,它需要迭代处理所有的key索引;
(7)当所有map和reduce任务都完成以后,主服务器负责通知用户程序,用户程序汇总各reduce任务的输出文件得到最终结果,或者将这些输出文件当作下一轮MapReduce计算的输入数据。
为什么Google公司提出MapReduce这种分布式模型后得到了这么多的关注呢?
这主要还是因为Google公司采用这种模型解决了其实际问题,所以大家才会这么重视MapReduce技术的研究。
我们知道,Google公司最成功的应用应该算是其搜索引擎了,搜索引擎中的一个重要工作就是需要统计爬虫程序搜集的海量网页数据中各个单词出现的次数。根据相关报道,Google搜集的网页所占存储空间超过400TB,假设一台计算机以30MB/s的速度读取这些数据,将会至少需要4个月的时间,而在其集群系统采用MapReduce方法后可以将该时间缩短到3个小时。
Hadoop的MapReduce又是怎样的?
如图4所示,Hadoop在其MapReduce模型中定义了用户程序(ClientProgram)、作业服务器(Job Tracker)和任务服务器(Task Tracker)三种角色。

图4 Hadoop的MapReduce
可以看出,Hadoop的MapReduce与Google的MapReduce非常相似,其作业服务器类似于Google的主服务器,任务服务器类似于Google的工作服务器。
实际上,Hadoop开源项目的MapReduce子项目也正是参考Google关于MapReduce的论文设计实现的,所以两者如此相似也就不足为奇了。