

发布时间: 2022-03-09 16:08:53 发布者:togogo |
Spark框架是一个快速且API丰富的内存计算框架。Spark采用Scala语言编写,Scala是基于JVM的语言,性能开销小。
在Spark,一切计算都是基于RDD句柄来进行操作的。RDD就像一个数据容器,可以有输入口,可以有输出口。在内存中,Spark使用Tachyon——一种类似于内存中的HDFS的内存分布式存储框架,这样使得读写速度有了极大的提高(官方说是100倍)。
Spark提供了大量的应用程序接口,如Python、Scala、Java以及SQL接口,还可以使用HDFS、Hive、Cassandra等作为数据源,它的外部接口非常丰富,而且自身支持了很多组件,主要组件如图所示。
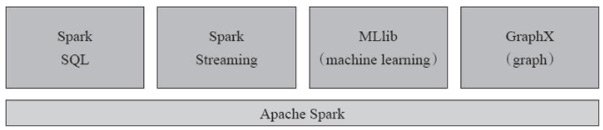
Spark的组件
1.Spark Core
Spark Core是指Spark的核心功能,包括任务调度、内存分配回收、RDD(弹性分布式数据集,Resilient Distributed Dataset)操作、API处理等,是Spark的核心组件。
2.Spark SQL
Spark SQL最早采用了Apache Hive的SQL版本,当时被称作Shark,它可以让用户通过SQL来操作RDD,,而且能够支持交互方式的数据访问。但是因为效率不高,在1.0版本重新编写了Spark SQL来取代HQL(Hive版本的SQL,也有的资料上会写作HiveQL),使用SQL操作Spark RDD大大降低了Spark编程的难度。
3.Spark Streaming
Spark Streaming是流式计算组件。在Spark Streaming里,流处理实际用的是Micro-Batch的方式,即微批处理。什么是Micro-Batch?Batch是批处理的意思,就是一次性处理需要的事务,中间不需要和人进行交互。而Micro-Batch处理的对象是以毫秒为单位的微小的批处理。
可以在内存里把输入的流数据“攒”够1秒、2秒或者其他时间长度,然后把攒起来的数据当做一个RDD块。一个RDD块上能够进行什么计算和操作,那么这个Micro-Batch上就能够进行同样的计算和操作。为了避免提交作业过于频繁而导致开销占比过大的问题,通常不推荐去做毫秒级别的Micro-Batch,请大家注意这点。
4.MLlib
MLlib是Spark的机器学习(ML)组件,提供了大量的可集群化的算法,包括聚类、分类、逻辑回归、协同过滤等。
5.GraphX
GraphX是可以进行集群化的图形计算和图形挖掘组件。这种组件非常适合用于微信、微博等各种社交网络产品的用户关系或者产品关系计算,这比用笛卡儿积的方式去做还是轻量很多。
这些封装好的组件都为使用Spark提供了很大的便利,再加上友好的API、比Hadoop更快的处理速度,使Spark逐渐抢占Hadoop的市场份额,在开源大数据计算中出现的频率越来越高。接下来安装Spark并用Spark来演示如何进行单词统计(WordCount)。
上一篇: 怎么安装Spark
下一篇: 如何安装Hadoop

微信

公众号










