

发布时间: 2022-02-17 11:49:08
什么是机器学习?事实上,机器学习是一系列技术的一部分,这些技术通常被归为人工智能(AI)。这个词曾经让科幻小说爱好者梦想到两足机器人和有意识的机器,或者梦想到一个机器奴役人类的矩阵世界。
事实上,人工智能包括允许计算系统使用任何技术来模拟人类智能的所有技术,从非常先进的技术逻辑到基本的if-then-else决策循环。任何使用规则进行决策的计算机都属于这个领域。
一个简单的示例是可以帮助我们找到停车位置的应用程序。每隔一段时间对司机位置的GPS读数会计算出司机开车的速度。由一个基本的阈值系统来确定司机是在开车(例如,“如果速度大于20英里/小时或30公里/小时,则开始计算速度”)。当司机停车并断开与汽车蓝牙系统的连接时,应用程序只会记录下断开连接时的位置。这是车停放的位置。除人工智能(电脑知道司机把车停在哪里)外,规则集非常简单。
在更复杂的情况下,静态规则不能简单地插入到程序中,因为它们需要可以更改或不完全理解的参数。
一个典型的例子是在计算机上运行的听写程序。该程序被配置为识别字典中每个单词的音频模式,但它不理解语音的特定内容——重音、音调、速度等。我们需要录制一组确定的句子,以帮助该工具将已知单词与读单词时发出的声音匹配起来。这个过程叫作机器学习。
ML关心的是计算机需要接收一组处理后的数据以帮助更高效地执行任务的任何过程。ML是一个广阔的领域,但可以简单地分为两大类:监督学习和无监督学习。
1.监督学习
在监督学习中,用已知正确答案的输入训练机器。例如,假设我们正在训练一个系统来识别矿井隧道中何时有人。配备有基本摄像头的传感器可以捕捉形状,并将其返回给一个计算系统,该系统负责确定形状是人还是其他物体(比如一辆汽车、一堆矿石、一块石头、一块木头等)。
使用监督学习技术,成百上千的图像被输入到机器中,每个图像都进行了标记(在本例中为人类或非人类)。这就是所谓的训练集。
算法用于确定图像之间的公共参数和共同点差异。比较通常在整个图像的尺度上进行,或者逐像素进行。图像被调整为具有相同的特征(分辨率、颜色深度、中心图形的位置等),并对每个点进行分析。人类图像在特定位置具有特定类型的形状和像素(对应于脸、腿、嘴等的位置)。将每幅新图像与一组已知的“良好图像”进行比较,并计算一个偏差,以确定新图像与一般人类图像的差异,从而确定显示的是一个人类图形的概率。这个过程叫作分类。经过训练,机器应该能够识别人类的形状。
在实际进行现场部署之前,通常使用未标记的图片对机器进行测试(根据使用的ML系统,这称为验证或测试集),以验证识别级别是否处于可接受的阈值。如果机器没有达到预期的成功水平,就需要更多的训练。
在其他情况下,学习过程并不是将其划分为两个或多个类别,而是寻找一个正确的值。例如,管道中石油的流速是由管道的大小、石油的黏度、压力等几个因素决定的。当使用测量值来训练机器时,机器可以预测出新的、未测量的黏度的流速。这个过程叫作回归;回归预测数值,而分类预测类别。
2.无监督学习
在某些情况下,监督学习并不是机器帮助人类做出决策的最佳方法。假设我们正在处理来自小型发动机制造工厂的物联网数据。生产的发动机中平均约有0.1%需要进行调整,以防止以后出现缺陷,我们的任务是在它们安装到机器并从工厂发货之前识别它们。
由于有数百个部件,因此可能很难检测出潜在的缺陷,而且几乎不可能训练机器来识别可能不可见的问题。但是,我们可以测试每个发动机并记录多个参数,如声音、压力、关键部件的温度等。一旦数据被记录下来,我们就可以用图像表示这些元素之间的关系(例如,温度是压力、声音与转速随时间变化的函数)。
然后,我们可以将这些数据输计算机,并使用数学函数来查找组。例如,我们可以决定根据发动机在给定温度下发出的声音对其进行分组。操作这种分组的标准函数K-means集群可以找到一组发动机的平均值(例如,温度的平均值、声音的平均值)。
使用这种方法对发动机进行分组,可以快速发现属于同一类别的几种发动机(如链锯式小型发动机、割草机式中型发动机)。所有相同类型的发动机产生的声音和温度与同一组的其他成员相同。在发动机分组中偶尔会有一台发动机显示出异常的特性(略微超出预期的温度或声音范围)。这是我们用于手动评估的发动机。与这一确定过程相关的计算过程称为无监督学习。
这种类型的学习是无监督的,因为事先没有“好”或“坏”的答案。这是一个群体行为的变化,计算机可以学习到一些不同的东西。当然,发动机的这个例子非常简单。在大多数情况下,参数是多维的。换句话说,要计算成百上千个参数,并在多个参数中累积较小的偏差用于识别异常。
图1显示了这种分组和偏差识别逻辑的一个示例,绘制了3个参数(组件1、组件2和组件3),并发现了4个不同的组(集群)。我们可以看到一些点远离各自的组。我们应该对显示这种“集群外”特性的单个设备单独进行更仔细的检查。
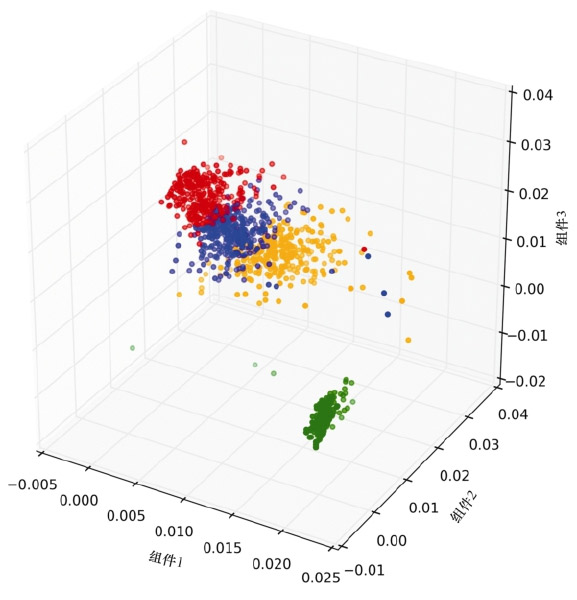
图1 聚类和偏差检测实例
3.神经网络
处理多个维度需要大量的计算能力。也很难确定要输入哪些参数,以及哪些组合变量会引发警告。同样,监督学习只有在训练集很大的情况下才有效;训练集越大,预测的准确性越高。这一要求在一定程度上使ML在20世纪80年代和90年代逐渐消失。训练机器的过程通常被认为过于昂贵和复杂。
自21世纪初以来,廉价的计算能力以及对超大数据集的访问(通过互联网共享)使ML重新焕发了活力。与此同时,所使用的算法的效率也取得了巨大进步。
以采矿作业中的人体形状识别为例。区分人与车很容易。计算机可以识别出人类有不同的形状(如腿或手臂),而车辆没有。区分人类和其他哺乳动物要困难得多(尽管非人类的哺乳动物在矿井中并不常见)。
同样的道理也适用于区分小货车和货车。当我们看到它们时可以轻松分辨出来,但是训练一台机器来区分它们需要的不仅仅是基本的形状识别。
这就是神经网络发挥作用的地方。神经网络是模拟人类大脑工作方式的ML方法。当看到一个人时,大脑的多个区域被激活,用来识别颜色、动作、面部表情等。大脑将这些因素结合起来,得出“看到的形状是人类”的结论。神经网络模仿同样的逻辑。信息经过不同的算法(称为单元)处理,每个算法负责处理信息的一个方面。一个单元计算的结果值可以直接使用,也可以输入到另一个单元进行进一步的处理。
在这种情况下,神经网络有几个层次。例如,处理人类图像识别的神经网络可能在第一层有两个单元来确定图像是否有直线和锐角,因为车辆通常有直线和锐角,而人体没有。
如果图像成功通过第一层(因为没有或只有一小部分的锐角和直线),第二层可能会寻找不同的特征(是否存在面孔、手臂等),然后第三层可能会将图像与各种动物的图像进行比较,并得出结论“该形状是人(或不是人)”。神经网络之所以效率最高,是因为每个单元处理一个简单的测试,计算速度相当快。该模型如图2所示。
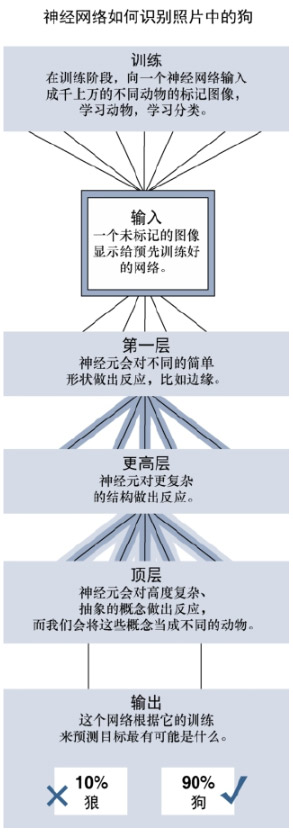
图2 神经网络的例子
相比之下,旧的监督ML技术会在训练阶段将人体图像与潜在的数十万幅图像进行逐像素比较,实现困难且成本较高(需要大量训练),操作起来也比较慢。神经网络一直是许多研究工作的主题,其中多项研究和优化工作已经检查了单元和层的数量、每层处理的数据类型,以及用于处理数据的算法类型和组合,以使处理特定应用程序的效率更高。
图像处理可以通过某些类型的算法进行优化,而这些算法对于人群运动分类可能不是最优的。在这种情况下,可能会发现另一种算法,它将彻底改变这些运动的处理和分析方式。从某种意义上说,神经网络依赖于这样一种思想,即信息被分成几个关键部分,每个组成部分都被赋予一个权重。
权重的比较共同决定了这个信息的分类(没有直线+脸+微笑=人类)。当一个层的结果被输入另一层时,这个过程被称为深度学习(“深度”是因为学习过程不止有一个层)。
深度学习的一个优点是,拥有更多的层可以实现更丰富的中间处理和数据表示。在每一层,数据都可以被格式化,以便下一层更好地利用。这个过程提高了整体结果的效率。
上一篇: 大数据分析工具和技术
下一篇: STP收敛时间

微信

公众号












