

发布时间: 2018-01-28 02:14:27
什么是Hive:
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 1、数据仓库的定义 数据仓库是一个面向主题的、集成的、稳定的、反映历史变化的、随着时间的流逝发生变化的数据集合。它主要支持管理人员的决策分析。 数据仓库收集了企业相关内部和外部各个业务系统数据源、归档文件等一系列历史数据,最后转化成企业需要的战略决策信息。 面向主题:根据业务的不同而进行的内容划分; 集成特性:因为不同的业务源数据具有不同的数据特点,当业务源数据进入到数据仓库时,需要采用统一的编码格式进行数据加载,从而保证数据仓库中数据的唯一性; 非易失性:数据仓库通过保存数据不同历史的各种状态,并不对数据进行任何更新操作。 历史特性:数据保留时间戳字段,记录每个数据在不同时间内的各种状态。 2. 数据仓库和数据库的区别 数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID) 为什么使用Hive 1:直接使用hadoop所面临的问题 人员学习成本太高 项目周期要求太短 MapReduce实现复杂查询逻辑开发难度太大 2:为什么要使用Hive 操作接口采用类SQL语法,提供快速开发的能力。 避免了去写MapReduce,减少开发人员的学习成本。 扩展功能很方便。
Hive的特点
可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
容错
良好的容错性,节点出现问题SQL仍可完成执行。
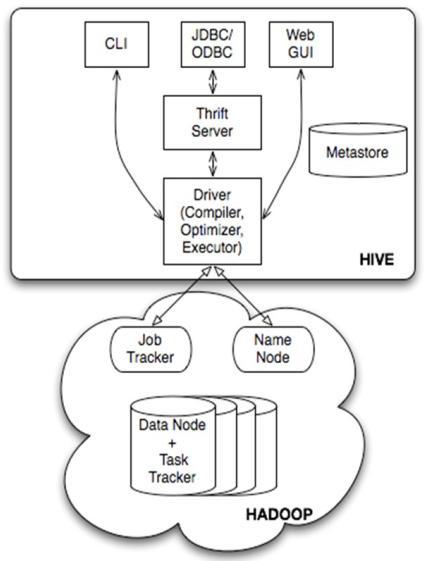
Hive架构
Jobtracker是hadoop1.x中的组件,它的功能相当于: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
基本组成 用户接口:包括 CLI、JDBC/ODBC、WebGUI。 元数据存储:通常是存储在关系数据库如 mysql , derby中。 解释器、编译器、优化器、执行器。各组件的基本功能 Ø 用户接口主要由三个:CLI、JDBC/ODBC和WebGUI。其中,CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。 元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
Hive利用HDFS存储数据,利用MapReduce查询数据

Hive与传统数据库对比

总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
1. 查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。 2. 数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。 3. 数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。 4. 数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO ... VALUES 添加数据,使用 UPDATE ... SET 修改数据。 索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描 Hive的数据存储 1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等) 2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。 3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。 db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹 table:在hdfs中表现所属db目录下一个文件夹 external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径 普通表: 删除表后, hdfs上的文件都删了 External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了 partition:在hdfs中表现为table目录下的子目录 bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
上一篇: {大数据}HIVE的安装部署
下一篇: {大数据}Kafka Java API

微信

公众号




