

发布时间: 2018-01-17 23:25:42
根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。

为什么要学习Spark Streaming
1.易用
2.容错 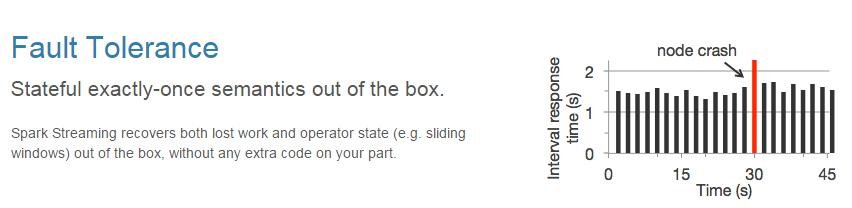
3.易整合到Spark体系

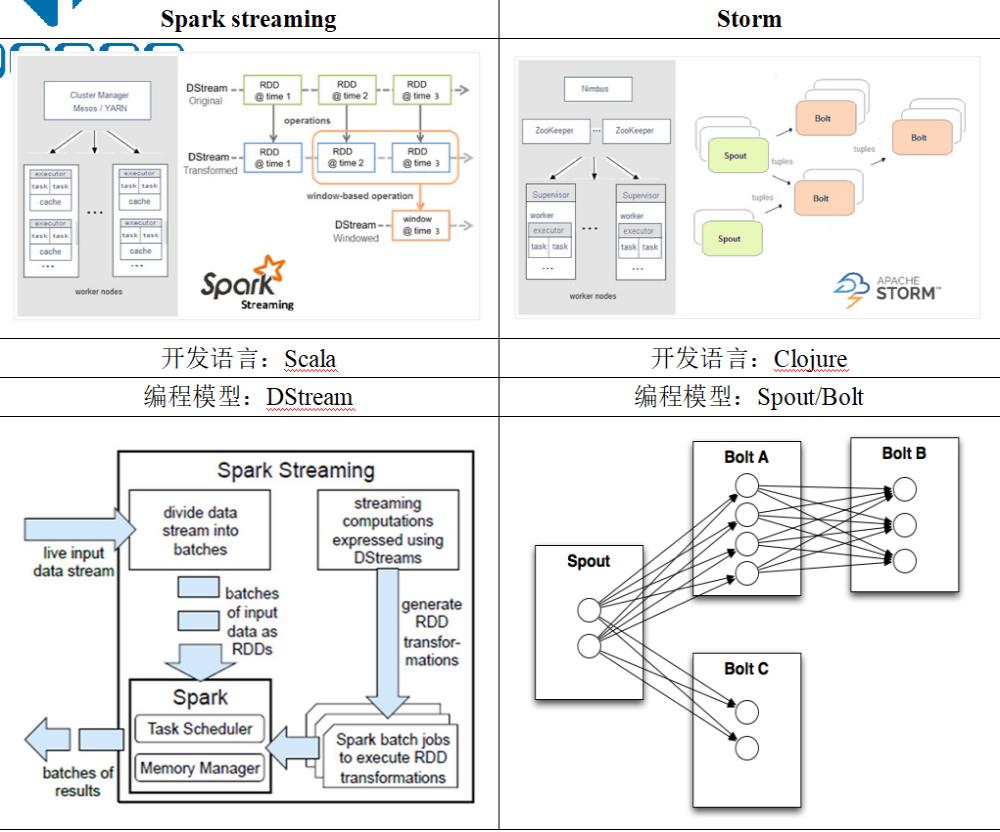
Spark streaming与Storm的对比:
DStream:
什么是DStream:
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:
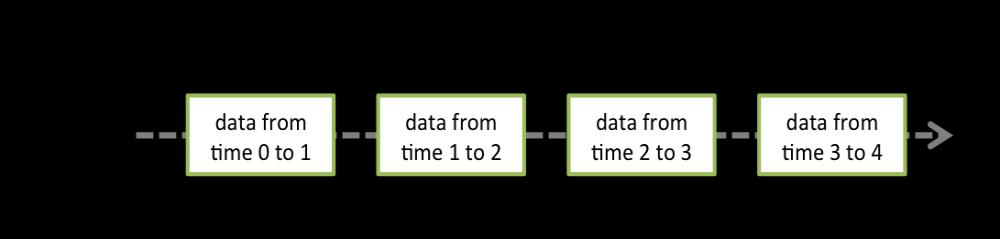
计算过程由Spark engine来完成
DStream相关操作:
DStream上的原语与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
Transformations on DStreams:
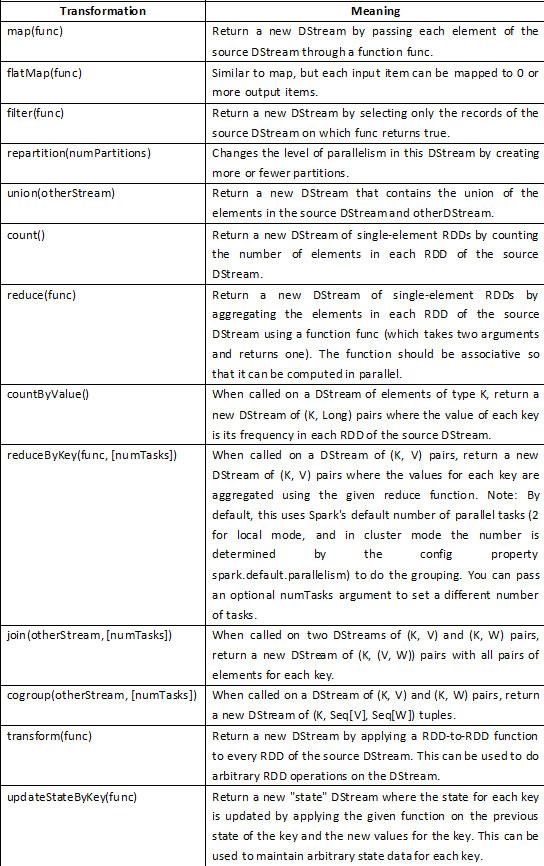
特殊的Transformations
1.UpdateStateByKey Operation
UpdateStateByKey原语用于记录历史记录,上文中Word Count示例中就用到了该特性。若不用UpdateStateByKey来更新状态,那么每次数据进来后分析完成后,结果输出后将不在保存
2.Transform Operation
Transform原语允许DStream上执行任意的RDD-to-RDD函数。通过该函数可以方便的扩展Spark API。此外,MLlib(机器学习)以及Graphx也是通过本函数来进行结合的。
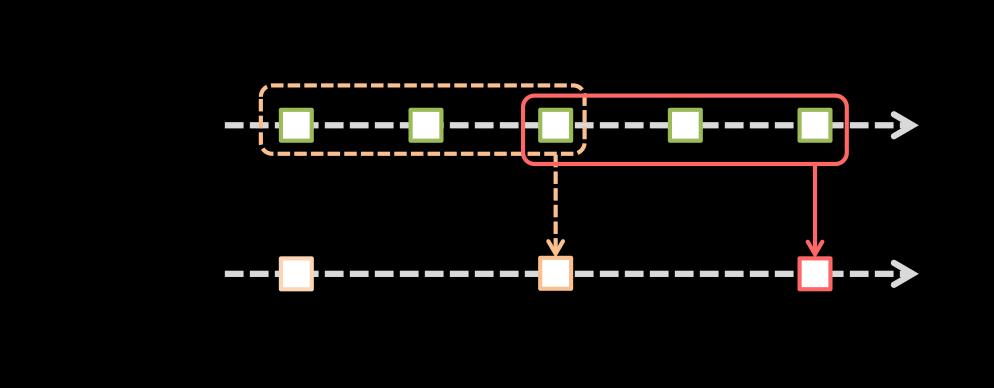
3.Window Operations
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态
Output Operations on DStreamsOutput Operations可以将DStream的数据输出到外部的数据库或文件系统,当某个Output Operations原语被调用时(与RDD的Action相同),streaming程序才会开始真正的计算过程。
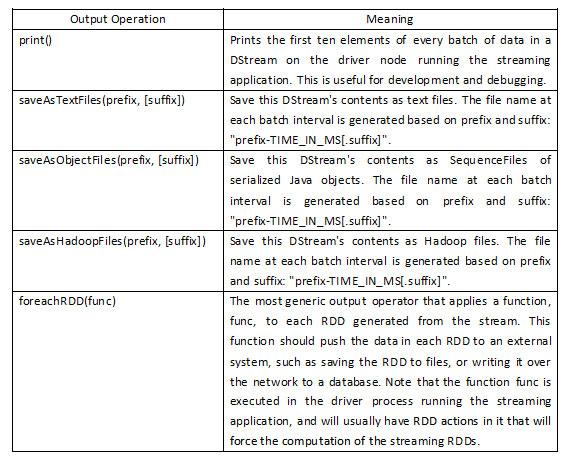
实战用:
Spark Streaming实现实时WordCount
架构图:
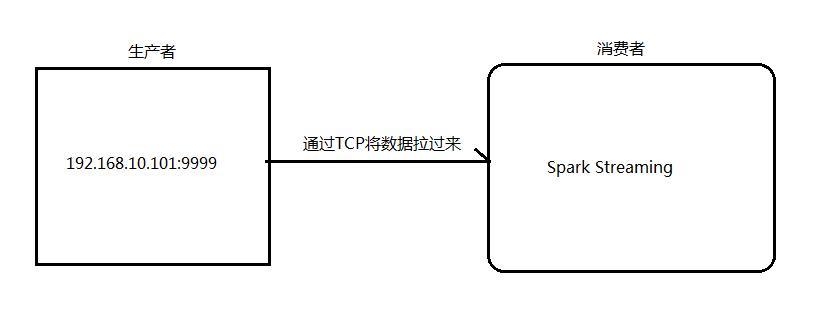
1.安装并启动生成者
首先在一台Linux(ip:192.168.10.101)上用YUM安装nc工具
yum install -y nc
启动一个服务端并监听9999端口
nc -lk 9999
2.编写Spark Streaming程序
package net.togogo.stream
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Seconds
object NetworkWordCount {
def main(args: Array[String]) {
//设置日志级别
LoggerLevels.setStreamingLogLevels()
//创建SparkConf并设置为本地模式运行
val conf = new SparkConf().setAppName("NetworkWordCount")
//设置DStream批次时间间隔为2秒
val ssc = new StreamingContext(conf, Seconds(2))
//通过网络读取数据
val lines = ssc.socketTextStream("hdp08", 9999)
//将读到的数据用空格切成单词
val words = lines.flatMap(_.split(" "))
//将单词和1组成一个pair
val pairs = words.map(word => (word, 1))
//按单词进行分组求相同单词出现的次数
val wordCounts = pairs.reduceByKey(_ + _)
//打印结果到控制台
wordCounts.print()
//开始计算
ssc.start()
//等待停止
ssc.awaitTermination()
}
}
/home/hadoop/apps/spark/bin/spark-submit \
--class net.togogo.sparkdemo.stream.NetworkWordCount \
--master spark://hdp08:7077 \
/home/hadoop/sparkdemo.jar
3.启动Spark Streaming程序
4.在Linux端命令行中输入单词
[hadoop@hdp08 ~]$ nc -lk 9999
hello hello spark spark
5.在控制台中查看结果
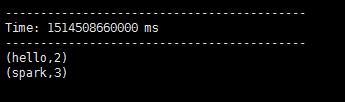
问题:结果每次在Linux段输入的单词次数都被正确的统计出来,但是结果不能累加!如果需要累加需要使用updateStateByKey(func)来更新状态,下面给出一个例子:
package net.togogo.stream
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.{StreamingContext, Seconds}
object NetworkUpdateStateWordCount {
/**
* String : 单词 hello
* Seq[Int] :单词在当前批次出现的次数
* Option[Int] : 历史结果
*/
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))}
}
def main(args: Array[String]) {
LoggerLevels.setStreamingLogLevels()
val conf = new SparkConf().setAppName("NetworkUpdateStateWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
//做checkpoint 写入共享存储中
ssc.checkpoint("hdfs://hdp08:9000/work/wcout")
val lines = ssc.socketTextStream("hdp08", 9999)
//reduceByKey 结果不累加
//val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
//updateStateByKey结果可以累加但是需要传入一个自定义的累加函数:updateFunc
val results = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
/home/hadoop/apps/spark/bin/spark-submit \
--class net.togogo.sparkdemo.stream. NetworkUpdateStateWordCount \
--master spark://hdp08:7077 \
/home/hadoop/sparkdemo.jar
/home/hadoop/apps/spark/bin/spark-submit \
--class net.togogo.stream.NetworkUpdateStateWordCount \
--master spark://hdp08:7077 \
/home/hadoop/schema.jar
上一篇: {大数据}Kafka
下一篇: {大数据}Spark SQL
 18922156670
18922156670













